
8 April 2020
Big Data & Predictive Analytics – Beyond the Buzzwords
Every business today needs one essential piece of kit: a crystal ball. If you could predict the future, risk and…

Sales & Marketing Insiders
Testimonials, tips and tricks to improve your sales and marketing efficiency
21 September 2017
A survey undertaken by The Economist on behalf of Capgemini in 2011, entitled “The Deciding Factor: Big Data & Decision Making”, concluded that data was playing an increasingly significant role in decision making, but that so far “saying is one thing and doing is another” The survey, which involved 600 decision makers around the world and in all industry sectors, aimed to measure the use of Big Data in the decision-making chain of their companies.

This report also demonstrated that that those who played the game and practiced what they preached fared better than the others. However, 42% had had difficulties interpreting unstructured content, and 85% singled out not volume itself but the ability to analyse and act on the data.
This survey had the virtue of focusing on a phenomenon that many described intuitively, without always being able to justify it with numbers: technology enables shifts and provides an undeniable advantage; but it is nothing without human control, without analysis, interpretation and the necessary emotional intelligence, which are often behind the right decisions.
5 years on, what’s the situation? Have we made progress? What should we pay particular attention to with regard to decision making based on Big Data?
Initially, there is some confusion between data, information, knowledge and wisdom. Yet, theories on understanding have existed for a long time. That of Russell Ackoff is the most prevalent but it is neither the first nor the last. Scott Carpenter*, in an online article, summarised the main avatars here:

In addition, Ackoff went as far as to develop hypotheses on the percentage of time devoted to each of the stages by the human brain: whereas data takes up 40% of the available brain time (he calls it “mental space”), the information layer will take up 30% of this time, knowledge 20%, with only 10% remaining for the higher layers. While Ackoff’s theory was developed in 1989, at a time when data research was a fairly arduous task and only partially automated (PCs were only just starting to become a common in the USA at that time), the period of significant automation that we’re experiencing today should enable us, according to Pr. Carpenter, to concentrate on the higher tasks, thus giving substance to the sentence attributed to Einstein who claimed that “Imagination is more important than knowledge”
Here, the question is whether Big Data, almost 30 years later, has changed the game? Has knowledge become a statistic? Do mathematic models enable us to do without humans? Are these decisions better because of these algorithms? To get a clearer picture of the question, I looked at a webinar organised by the University of Stanford in the USA, which, thanks to the miracles of technology, enabled me to obtain knowledge (this is already a point for which the accumulation of video data will have clearly had a positive result).

Firstly, a compromise needs to be made between operational decisions and strategic decision, not that one is more important than the other. Big Data certainly offers a high volume of data, a large variety and high velocity (the Meta Group’s famous founding 3V theory), but, according to the Stanford facilitators, there is no correlation between the relevance of the Data and its abundance, even if it were in exponential growth.
In fact, despite the lyrical musings of the technophiles, “we are only capable of scratching the surface” warned the Stanford webinar organisers: “only 0.5% of data is available for making decisions.” I had already heard of similar interpretations, which put the percentage of data effectively available for analysis at 1% (according to Information Builders). Whatever the figures are, all we know is that there really is no comparison between the volumes of effectively available data and the stratospheric volumes announced in all the conferences.
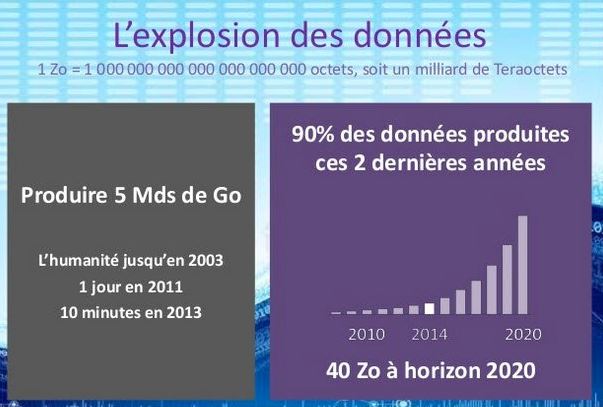
That’s not all: what has changed recently is that, in the past, we were capable of improving these algorithms. This is no longer the case. This is confirmed by Google’s Peter Norvig (the article is embargoed but available if you look hard enough) according to whom “we don’t have better algorithms at our disposal, we just have more data.” Likewise, the fact that we have more data does not guarantee better results. Not always, anyway.
In the future, it will no longer be access to data that is selective, because the data suppliers will be increasingly capable of supplying connecters and APIs. The game-changer will be their capacity to ask the right questions (the renowned decision process).
As supporting evidence, there are examples where the Big Data / human decision-making combination works very well. Many Big Data applications have thus focused on operational decisions (performance improvement) in a particular domain.
For example, Volvo Trucks has used Big Data in its inspection process for its professional vehicle fleet: this generates a significant volume of data, 1GO per truck and per hour, and enables the company to improve the maintenance scheduling, improve fuel-use efficiency, and remotely diagnose technical problems.
Other companies take this further and do not hesitate to use Big Data to inform their strategic decision-making process. This is the case for Persado, which uses algorithms enabling it to formalise its direct marketing messages via e-mail. Its Chief Marketing Officer describes this process as “a math problem that solves for the most persuasive message.”
There are also many, more traditional, examples in the health sector.

Thus, if we bring around departmental heads and Big Data experts (data scientists), not only can we perfect the retrospective approach to continuous improvement, but we can also make better forward-looking and strategic decisions.
On this point, the analysts facilitating our webinar are clear. James Matheson, from Smartorg, tells us “Big Data definitely changes the nature of content. However, in terms of decision processes, this is much less certain.”
Big Data will enable us, through data, to identify trends via extrapolation. On the other hand, with regard to discovering hidden trends, “you will still need humans, as in research and development.”
On this subject, Peter Thiel SV, creator of PayPal and author of ZERO TO ONE wrote: “It’s a very strange idea to believe that the future could resemble the past. Yet, that is the hypothesis being put forward by the science of statistics.”
So, we can perhaps conclude that it’s fairly pointless to look in our rear mirror. It even runs the risk of leading us towards bad decisions. For example, can we retrospectively imagine that, supplied with Big Data and relevant data, the decision makers at Digital Equipment (DEC), which went under in the 2000s, would have predicted the personal computers and distributed computing trends (which inexorably killed its mini-computer business)? In fact, those familiar with the sector know that everyone had seen this development coming for a long time. It is not the absence of data that led to this bad decision. Adding data would have changed nothing.
All things considered, the decision-making process has not changed that much over time. According to the Stanford webinar facilitators, conclusions that are conducive to leading to decisions can only come from a human analyst.
The very notion of the “right decision” is an eminently subjective notion, with results rarely measured in a binary manner (good or bad). So we just need to wait for machine learning and artificial intelligence to progress so much that machines will become endowed with intelligence and imagination. This is most definitely the area that I am most looking forward to artificial intelligence, because, although it is possible to reproduce rational intelligence up to a certain point, emotional intelligence—the mother of intuition—is much more difficult to reproduce. And in case we do succeed, I think, just like Professor Steven Hawking and a few others, that the human race will have every reason to be concerned.
In the meantime, in order to increase the relevance of business decisions through Big Data, multi-disciplinary teams need to be made, in order to best interpret the available data.
Based on these findings, and on the conclusion of the Carpenter report quoted above, you now know that, if you use Big Data in a relevant way, by fuelling a high-quality human decision-making process, you will have made the best use of these new technologies in order to make the right decisions.
8 April 2020
Every business today needs one essential piece of kit: a crystal ball. If you could predict the future, risk and…

4 March 2020
By multiplying data sources, predictive marketing can anticipate the requirements of leads and increase the conversion rate. It also rationalises…

26 February 2020
The first goal of a CRM system is to centralise the data concerning clients and leads that will then enable…

4 February 2020
5 Ways in Which Artificial Intelligence is Transforming B2B Marketing
Sparklane puts data at the service of lead generation and sales and marketing efficiency.
©2025 Sparklane

